The Helicone AI Gateway, Now On The Cloud!
 Juliette Chevalier· September 10, 2025
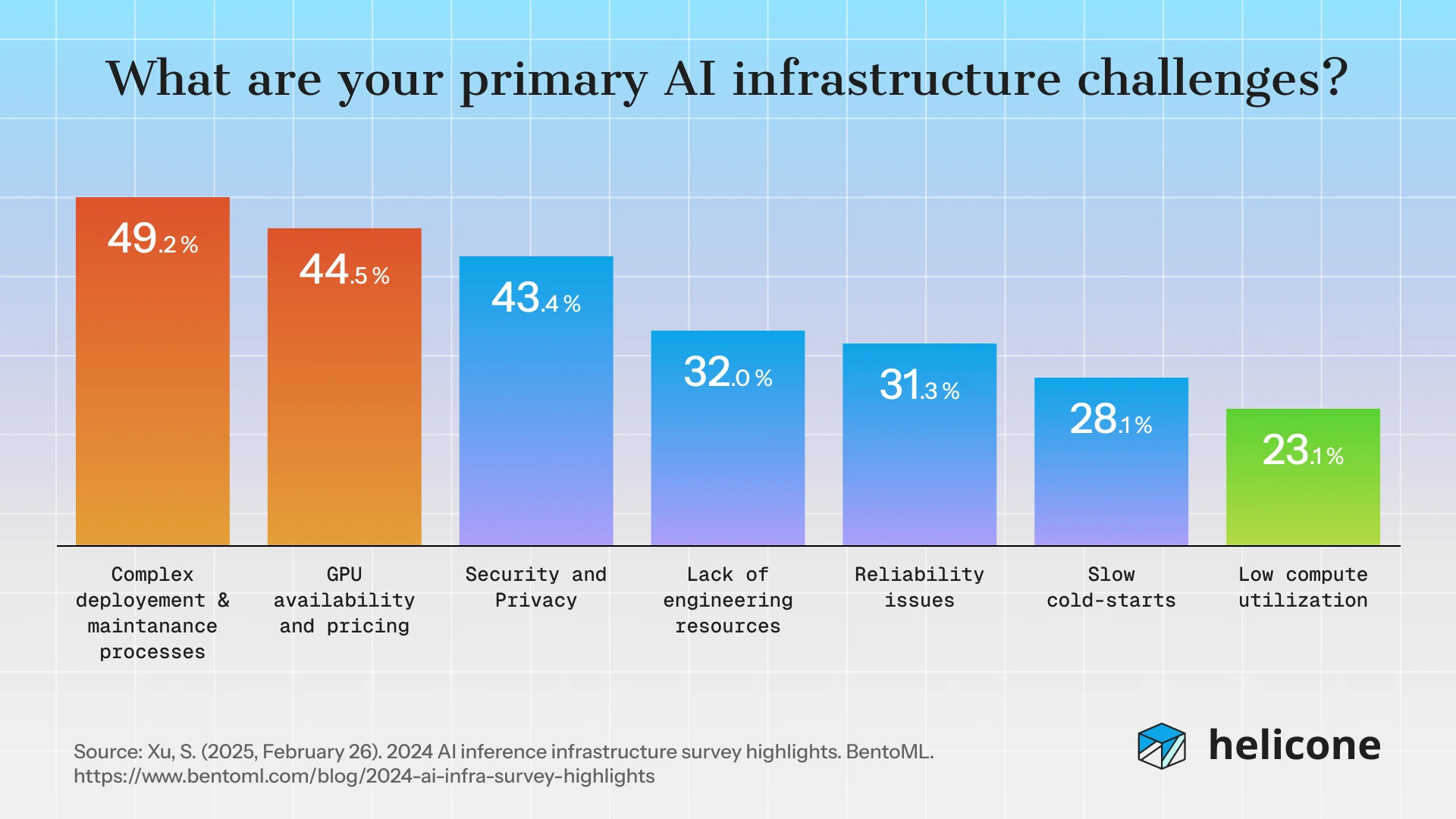
Juliette Chevalier· September 10, 2025Around 50%+ of engineers say integrating and managing multiple models is their #1 AI pain point. At the same time, over 90% of AI teams run 5+ models in production.
This means:
- API keys everywhere
- Custom logic for provider fallbacks
- Zero visibility when things break
- Different handling for rate limits, caching, and tracing
- Constantly updating code every time a new model is released
Engineers are spending too much time integrating infrastructure instead of shipping features.
That ends today.
Built by engineers who've felt the pain of multi-provider integrations, the Helicone AI Gateway is the missing infrastructure layer that every AI team eventually ends up building internally.
We abstract away all complexity, so you can focus on shipping by picking only your favorite models.
Request Early Access ⚡️
We're releasing access to customers every week! Join the waitlist to become an early tester today.
One API. 100+ models. Zero configuration, 0% markup.
Through the OpenAI API, the Helicone AI Gateway routes to 100+ models across all major providers - with observability embedded by default so never miss a trace.
// ❌ OLD WAY - multiple SDKs and endpoints
const openai = new OpenAI({ baseURL: "https://oai.helicone.ai/v1" });
const anthropic = new Anthropic({ baseURL: "https://anthropic.helicone.ai" });
const openaiResponse = await openai.chat.completions.create({
model: "gpt-4o",
messages: [...]
});
const anthropicResponse = await anthropic.messages.create({
model: "claude-3.5-sonnet",
messages: [...] // Different message format!
});
// ✅ NEW WAY - one SDK, all providers
const client = new OpenAI({
baseURL: "https://ai-gateway.helicone.ai",
apiKey: process.env.HELICONE_API_KEY // The only API key you need
});
const response = await client.chat.completions.create({
model: "gpt-4o-mini", // Works with any model: claude-sonnet-4, gemini-2.5-flash, etc.
messages: [{ role: "user", content: "Hello!" }]
});
What makes this different
You can see the Helicone AI Gateway as your one-stop model concierge.
- We handle provider authentication, so you don't have to worry about so many API keys and permissions.
- 99.99% uptime with automatic fallbacks routed to other providers offering the same model.
- We are constantly checking for model pricing and route you to the cheapest provider.
- Observability is embedded by default, so you never miss a trace again.
- Configure rate limits, caching, and guardrails under one unified platform.
- We protect you from prompt injections & data exfiltrations so your product is always protected against attacks.
All under a single unified bill you can top-up as needed, or bring your own key (BYOK).
Why Now?
The AI infrastructure landscape is consolidating around a few key patterns:
- Multi-provider is the new normal: Teams use OpenAI for chat, Claude for coding, and Gemini for image generation and interpretation. Single-provider architectures are increasingly rare (support coming soon!).
- Reliability is non-negotiable: AI is becoming mission-critical for products today. Downtime is both frustrating and expensive.
- Developer experience matters: Engineers want to ship features, not maintain infrastructure. Tools need to be easy to integrate, use, and maintain.
Get Started
The AI Gateway is available now in private beta.
- Existing customers get priority access to the cloud service.
- New teams are added to the waitlist weekly.
Request Early Access ⚡️
We're releasing access to customers every week! Join the waitlist to become an early tester today.